- Published on
Machine Learning Part 3: Optimality & Gradient Descent

In part 2 of this series, I briefly mentioned local versus global minimums and how we want the global minimum of a function. What are local and global minimums? How do we get the global minimum? In this blog post, I'll be covering local and global minimums as well as a numerical technique called gradient descent which allows us to reach the minimum.
Local versus Global minimum
Let's say we're looking at a range, , in a function, , and is a point in that range where . The point, , is a local minimum if for every in the range . It's easier to understand this jargon with a visual example.
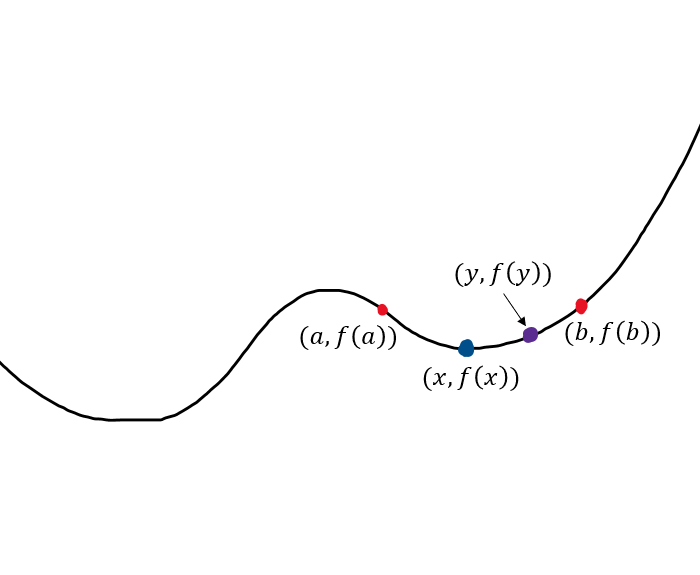
The point is the lowest point in the range therefore it is called a local minimum. The global minimum is the point, , where for all in the entire range of .
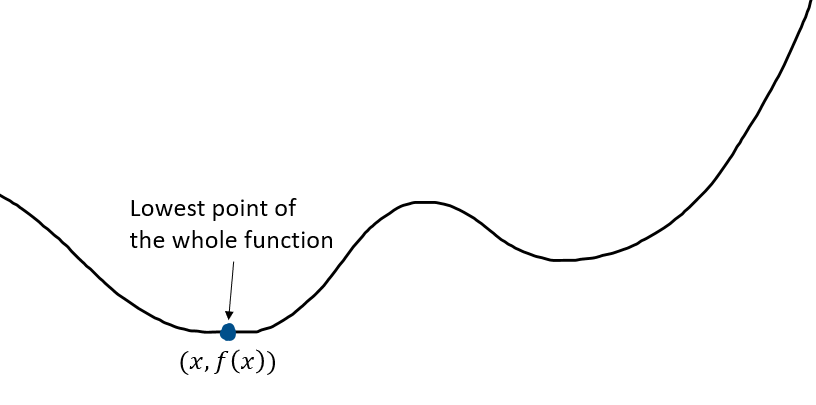
For a convex function, the local minimum is the global minimum. A minimum (or maximum) occurs wherever the derivative is equal to 0.
Minimizing MSE function
In part 2 of this series, we saw the mean squared error loss function along with its 1st and 2nd derivatives.
When training a machine learning model, we want the value of that minimizes . We already saw that MSE is a convex function so wherever the 1st derivative is equal to zero gives us the optimal value for .
The above assumes the rows of are the samples and the columns are the features. The inverse of a matrix is only valid for square matrices so what do we do if the matrix is not a square matrix? In this case we instead take the Moore-Penrose pseudo-inverse as denoted by a
The equation for the optimal value of the weights is called the closed-form solution. When we have a lot of inputs, calculating the closed-form solution can be computationally intense. It is often faster to use a numerical technique like gradient descent instead.
Gradient Descent
Gradient descent is an iterative technique to reach the minimum of the loss function and thus finding our optimal weight value.
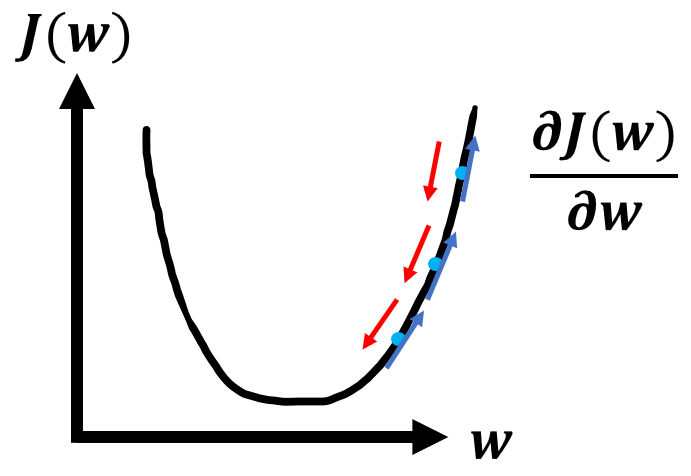
To start gradient descent, we can pick random values for and calculate the loss . We then take the derivative of the loss at which tells us which direction our minimum is at. The blue arrows on the above graph are the derivative which point upwards since the derivative is positive. We want to head towards the minimum so we head opposite of the blue arrows (red arrows). Here's the general procedure for gradient descent:
- Initialize randomly
- Repeat until minimum:
The learning rate, , can be thought of as the step size for each iteration. The superscript, , represents the current iteration. I want to explain a bit more about the 2nd step "Repeat until minimum". This is the update step but when does it actually occur? That depends on whether we are using Stochastic Gradient Descent (SGD), Batch Gradient Descent, or Mini-Batch Gradient Descent. Firstly, let's define a term called epoch. An epoch is a pass through all samples in a dataset. In SGD, we update our weights, , after each sample . Here's an example when using linear regression. Remember that the initial weights, , are random.
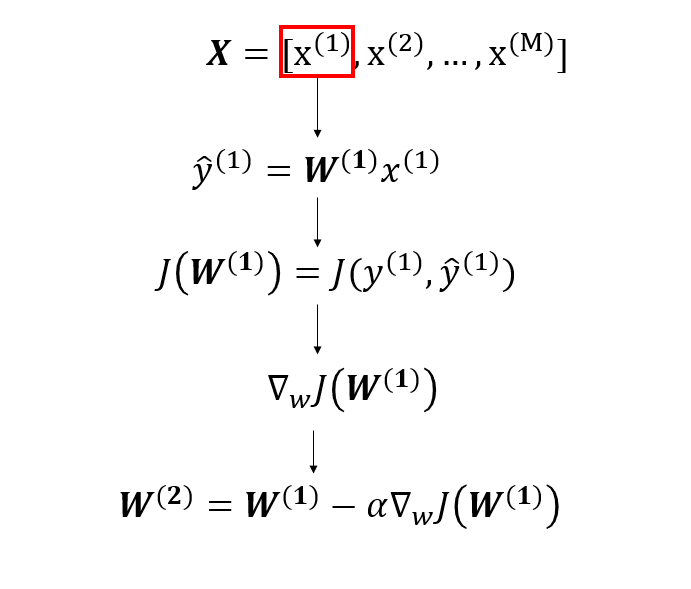
We take the first sample in our dataset and compute our predicted output, , which is then fed into our loss function, . Afterwards, we calculate the derivative of the loss function and use it to update our value for the weights so we now have . This is the weight we use when we repeat the above procedure for the next sample . We repeat the above procedure for each sample in our dataset. After we've done this for all of the samples, we've completed 1 epoch. We usually run multiple epochs until the values for our weights no longer change by a significant amount. In batch gradient descent, we go over the entire dataset before updating our weights.
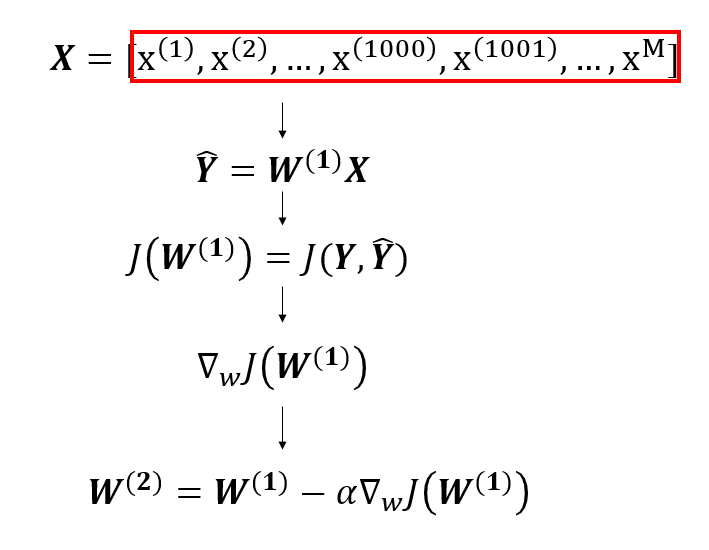
Batch gradient descent ends up being less noisy than SGD but it takes a long time per each iteration. Mini-Batch gradient descent is a middle ground where we split our dataset into mini-batches that we use to perform updates.
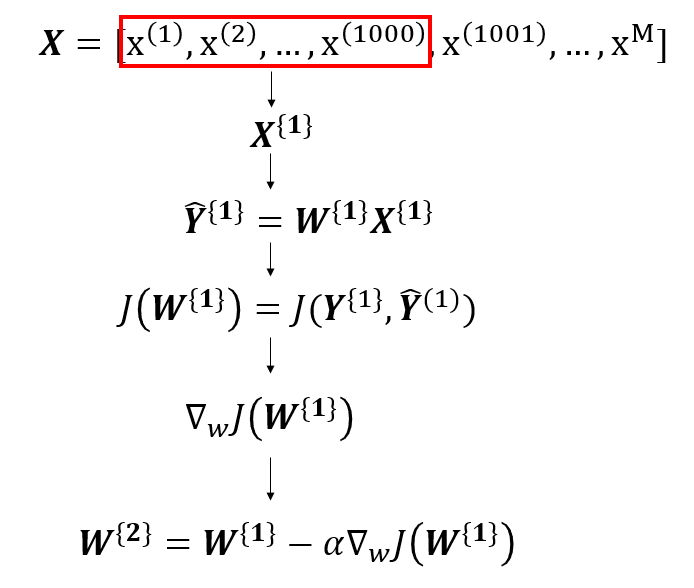
The mini-batches are represented by a curly brace. In the above example, the first 1000 examples are the first batch. We calculate our predictions using the first 1000 samples and sum our loss function for each sample in the batch. After we've gone through the entire batch, we then update our weights for the next batch.
Gradient descent is only one numerical way to find the minimum. There are many others such as RMSProp, Adam Optimization, and more. However, basic gradient descent will suffice for now.